Virtual flattening
Next » « PreviousAlongside all the conventional conservation work happening on the book, here at UCL we are experimenting with ways to “virtually restore” the book using a mix of imaging, computer vision, and computer graphics techniques.
Our approach is two-fold. First create a virtual 3D model of each page, and second flatten the 3D model into a 2D plane. It sounds fairly simple but is deceptively complex.
Creating detailed models of the pages requires a careful imaging process to try to get inside every crease and fold and capture every letter at as high a resolution as possible. The result is a set of 50 or so high-resolution images (for each page of the book). These are fed into a pipeline of computer programmes which (after a considerable amount of processing time) generates the 3D model.

Before virtual flattening
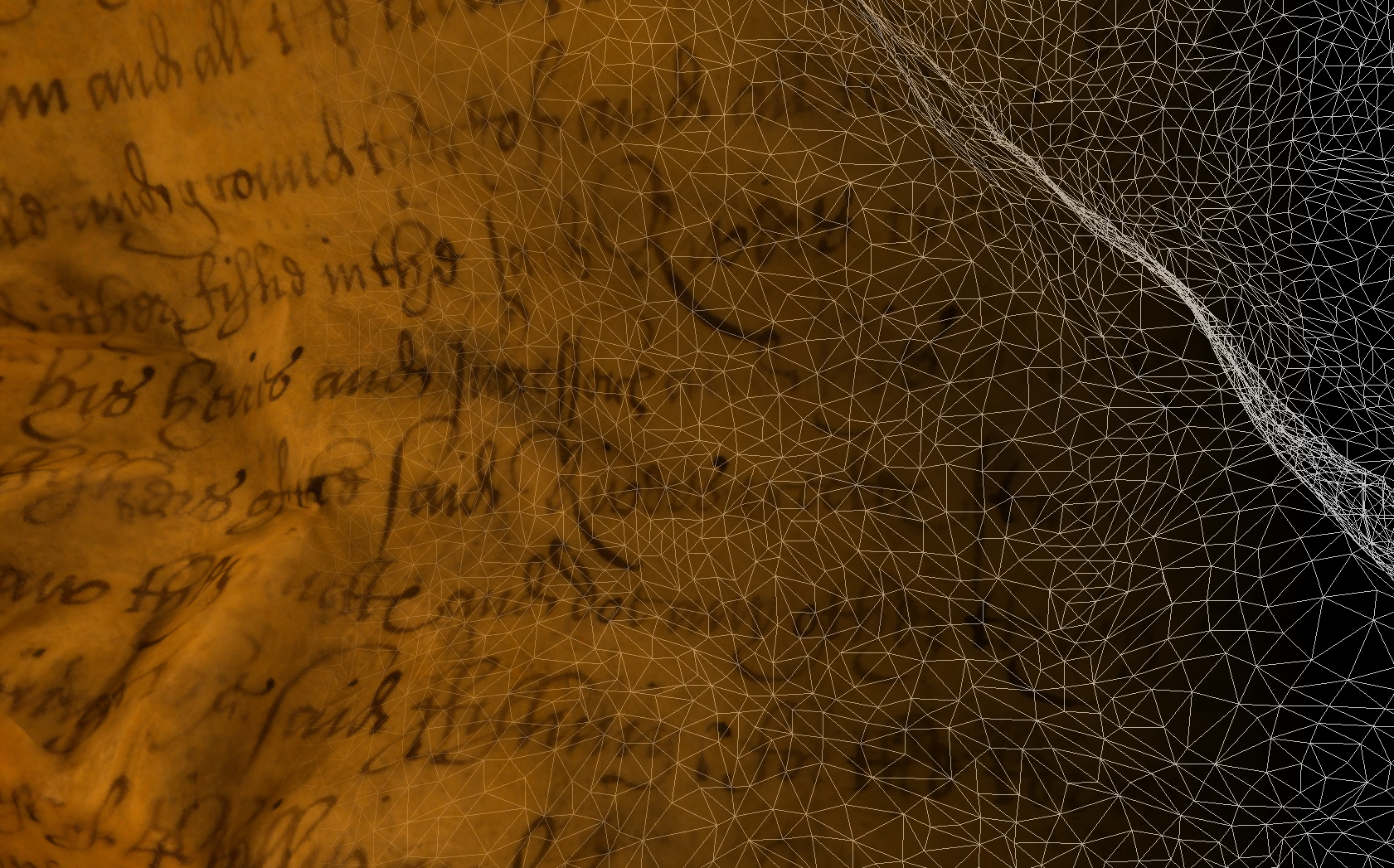
3D mesh
Then comes the problem of flattening the page in a sensible way. At first glance, it would seem that we want to just “unfold” the page as you would a crumpled piece of paper. However, the way the pages are distorted is not like crumpling a piece of paper and so there is no nice and easy way to “unfold” them. So now the problem becomes “how can we flatten the page into a 2D plane in such a way that the text does not become distorted”, and that is what we are trying to solve at the moment.

After virtual flattening